Serverless Data Processor using AWS Lambda, Step Functions and Fargate on ECS (with Rust 🦀🦀)
I have always been interested in finding new approaches to solve problems in the cloud. I spend a lot of time reading about various serverless technologies and finding new ways to use them to solve real world problems.
One other thing i have spent a lot of time working on lately in trying to learn Rust (no not the online game but the programming language). It has a lot of promise in making fast, efficient, and and safe code. It is challenging to learn and even more so to master i believe (I'm not there yet but it will surely be harder than what i've done so far).
AWS announced the GA of their AWS SDK for Rust in the fall and more people seem to be talking about it and using it. I think we will see the popularity grow but it will likely always be somewhat of a niche language.
We have been having lots of discussions on LinkedIn, X and at the #BelieveInServerless Discord around Rust and many different areas of serverless technology. If you want to join the growing community we have and want to interact with many serverless enthusiasts and experts please check it out at https://www.believeinserverless.com/
There have been some great articles and examples put out by the community and i'm sure we will see many more in 2024 and beyond.
Batch Data Processing Problem
The use case this article is centered around is having large batches of data to process in the cloud and doing that processing using a serverless approach. The problem statement and solution could be adopted to many different areas without many changes at all.
In this example we have a service that processes daily sales transactions for a number of businesses. This initial article involves the sales data for just a single company (or tenant) but i plan to expand on this in the future so that the environment is a multi-tenant one where we could offer this service to many businesses independently sharing the same infrastructure.
Once the data is uploaded we need to process it. The processing of this data is going to involve some specialized business logic which could be something like using the data to train or fine tune machine learning models, interacting with some legacy back end systems, or other processes that could take a variable amount of time. One of the key requirements that this environment has to handle is that the processing time for the data in many cases will be longer than the maximum runtime of an AWS Lambda function which is 15 minutes.
Another requirement of this system is that it has to handle updating the users via email or slack messages about the progress and processing results. Also the system has to be able to scale greatly when needed without provisioning any new infrastructure.
Sample Data
To show an example of the solution in action i will use some sample Sales data I found at Kaggle (https://www.kaggle.com/datasets/bekkarmerwan/retail-sales-dataset-sample-transactions) that i reorganized a little.
It includes 8 columns and here is a sample.
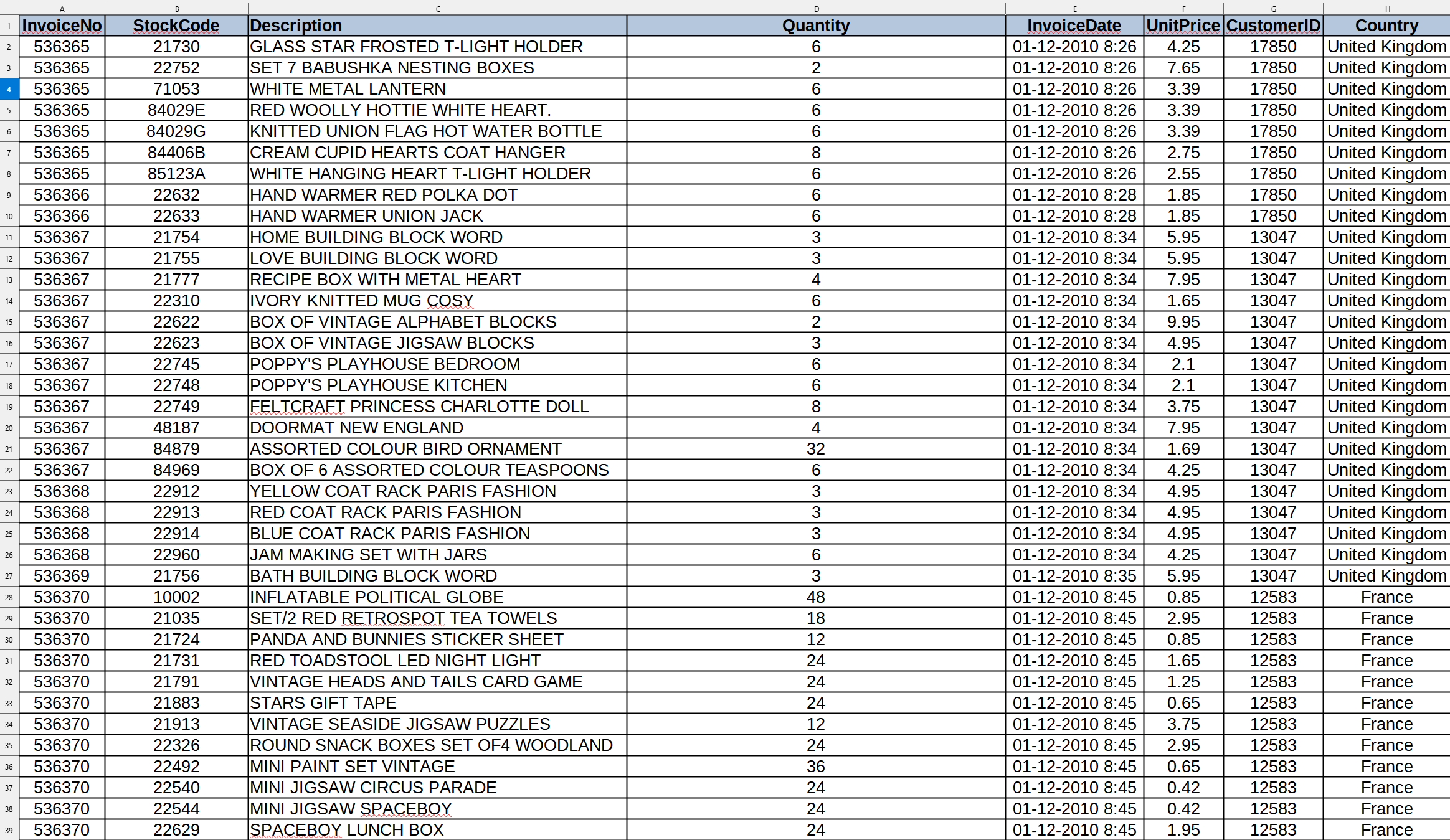
Each day (or some other frequency in the future) a zip file will be uploaded that contains a separate file for each business location. Each of those files is a JSON document containing the transactions at that location.
High Level Solution
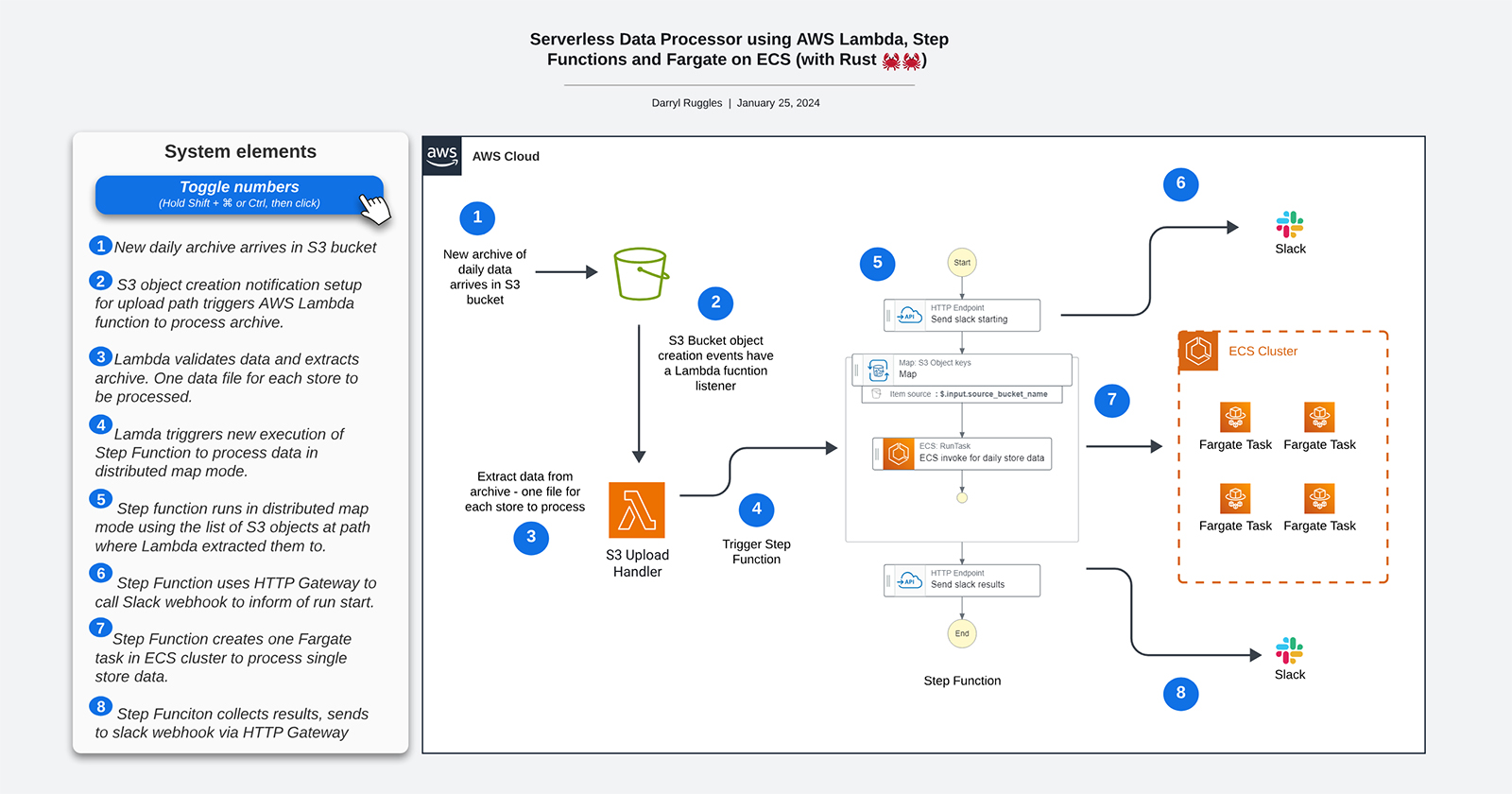
There are a few ways to solve this of course but one solution i wanted to explore is using AWS Step Functions (https://aws.amazon.com/step-functions/) to drive the whole process. Step Functions is a serverless workflow orchestration system. One part of it is support for a distributed map mode where you can run many parallel operations over a set of data. There are different approaches you can use to get the list of work items but the one that makes the most sense for this problem is iterating over all the objects in an S3 bucket based on a prefix.
One other nice thing Step Functions has is the ability to call HTTP endpoints directly from the Step Function environment without having to code another Lambda function or use some other mechanism. We will use this to make calls to a Slack webhook to update progress and show results.
As for how to deal with the actual processing of the data my go to suggestion is usually to use AWS Lambda functions. With the processing time being variable and me not wanting to try and break down the processing into multiple steps i need a different solution.
One great option in the serverless world for something like this is to run containers using AWS Fargate (https://aws.amazon.com/fargate/). Fargate is a service from AWS where you don't need to spin up or manage EC2 VMs to get access to compute. Also you don't need to pay for a container orchestration layer. You just provide a docker image and the specs of what you need to run it (cpu, ram, disk, etc) and AWS spins up the computer and runs the container.
You can use this in a couple of ways on AWS including with the Elastic Container Service (ECS) https://aws.amazon.com/ecs/ or within an Elastic Kuberneters Service (EKS) cluster. When used with EKS you will need to have an always on EKS control plane which will cost you money.
When using Fargate on ECS there is no such always on cost. ECS has a container orchestration layer but it does not cost you anything. So you only pay for the resources used in each Fargate container while it is running.
Upload to S3
When the file is uploaded to S3 there will be event listeners for the uploads/ path that will trigger a Lambda function. The Lambda function (called s3_upload_handler) takes the bucket and key info from the event and downloaded the zip file to it's local storage. It then unzips the file and then uploads the individual store location sales data files back to the same S3 bucket in the processed prefix.
I coded this using Rust and the AWS Rust SDK (https://aws.amazon.com/sdk-for-rust/). Please don't be too hard on me for the style as my Rust code is far from idiomatic but i'm getting there slowly. 🦀
After the Lambda processes the zip it will look like this:
Once all of this is done, the AWS Lambda function will initiate the Step Function state machine which will do the rest. The Lambda function gets the ARN of the step function to call by looking it up in the SSM Param Store. It could have also been passed as an environment variable to the Lambda but I had trouble getting all that to work in a Terraform and cargo lambda.
Here is a snippet of the code:
async fn function_handler(event: LambdaEvent<S3Event>) -> Result<(), Runtime_Error> {
tracing::info!(records = ?event.payload.records.len(), "Received request from S3");
let region_provider = RegionProviderChain::default_provider().or_else("us-east-1");
let config = aws_config::defaults(BehaviorVersion::latest())
// .profile_name("blog-admin")
.region(region_provider)
.load()
.await;
let ssm_client = SSM_Client::new(&config);
let state_machine_arn = get_parameter_value(&ssm_client, "/config/step_function_arn").await;
println!("State machine ARN: {}", state_machine_arn);
let s3_client = S3_Client::new(&config);
let mut the_key = String::from("");
let mut the_bucket: String = String::from("");
if event.payload.records.len() == 0 {
tracing::info!("Empty S3 event received");
} else {
// Lets determine the path of the zip file that was uploaded (should only be a single file)
for next in event.payload.records {
tracing::info!("S3 Event Record: {:?}", next);
tracing::info!("Uploaded object: {:?}", next.s3.object.key);
the_bucket = next
.s3
.bucket
.name
.expect("Trouble getting S3 bucket name for uploaded zip file");
tracing::info!("the_bucket: {:?}", the_bucket);
the_key = next
.s3
.object
.key
.expect("Trouble getting key for uploaded zip file");
tracing::info!("the_key: {:?}", the_key);
// Let's download the zip file
let _get_s3_result = download_object(&s3_client, &the_bucket, &the_key).await;
}
}
...
// We have extracted all the store sales files from the uploaded zip so lets start the state machine to process
// all the sales data files
let sfn_client = sfn::Client::new(&config);
let state_machine_input = format!(
"{{\"input\": {{ \"source_bucket_name\": \"{}\", \"bucket_path\": \"processed/{}/\" }} }}",
the_bucket, the_zip_file_name
);
println!("The state machine input is {}\n", state_machine_input);
// Start execution of the state machine to process the uploaded data
let sf_resp = sfn_client
.start_execution()
.state_machine_arn(state_machine_arn)
.input(state_machine_input)
.send()
.await;
match sf_resp {
Ok(_) => {
println!("Started state machine successully\n");
}
Err(e) => println!("Start state machine problem: {e:?}"),
}
Ok(())
}
AWS Step Functions
The Step Function (aka state machine) is configured to send messages using the HTTP Endpoint call mechanism to the Slack webhook URL i have. The repo does not have a valid webhook URL so if you're going to try the code out please get a valid webhook URL for slack. If you run it as is then the step function will fail.
The step function will first send a slack message with the info on what data it received and then start running the batch of all the files. This is done using the distributed map mode which will make a call to list all the objects in the passed in S3 bucket under the given prefix (path).
Each file will be processed by creating a Fargate Task (container) in ECS. Each task will be passed the S3 location of the file they are to process along with a Task Token to use to asynchronously call back to the Step Functions service to tell it their processing is complete and to pass back any results.
I have set the MaxConcurrency value in the step function definition to 10 which means at most 10 fargate containers will run at the same time. You can set this to be much higher to process all your data much quicker. You will have to look at all the quotas involved and handle getting throttled.
Here is a diagram of the flow:
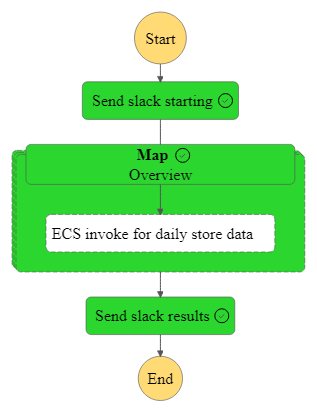
Fargate Tasks
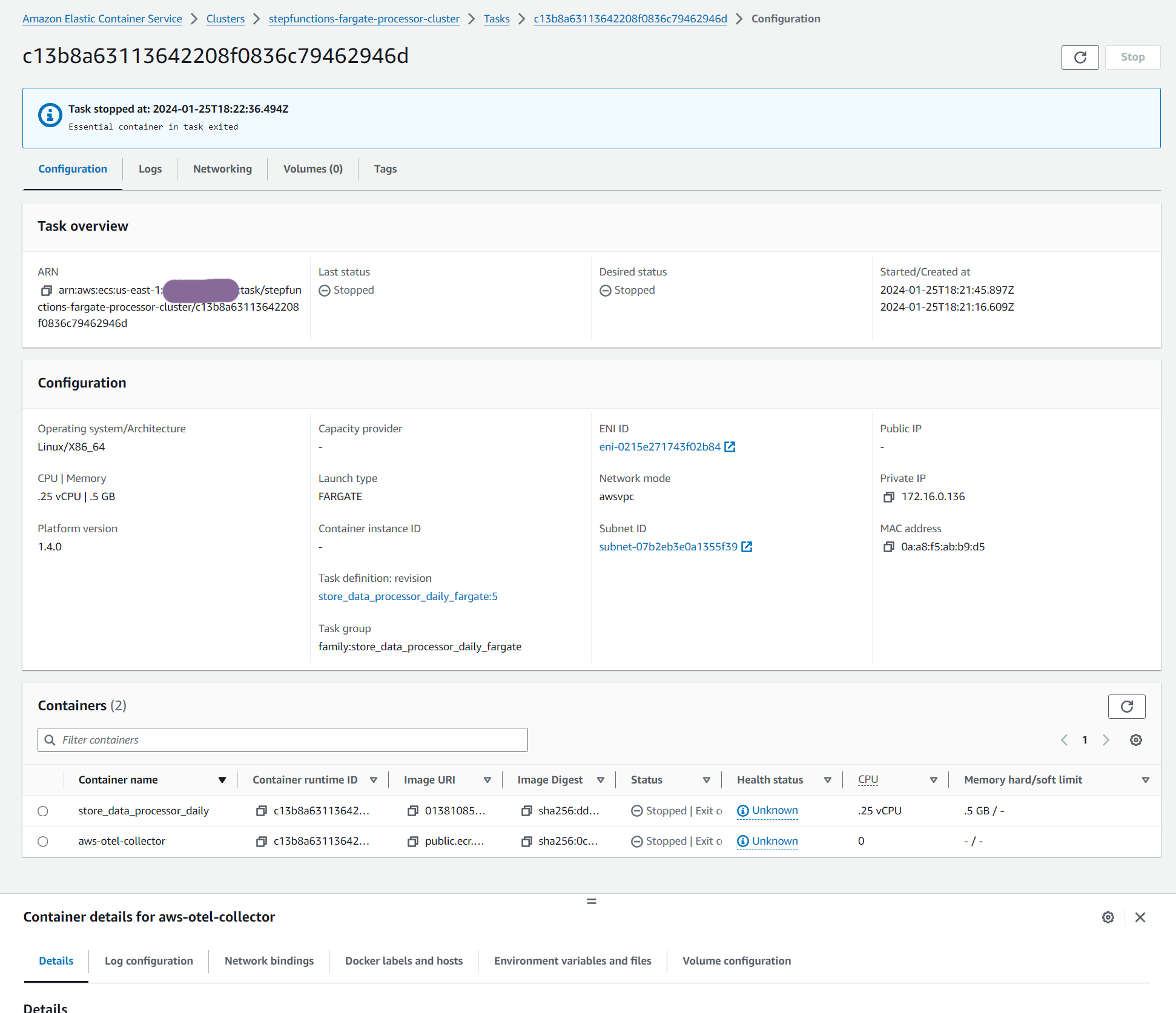
The Fargate tasks are using containers pushed to the AWS Elastic Container Registry (ECR) in a private repository. I have set the CPU and memory specs of the containers to the minimum (0.25 vCPU and 512MB of RAM) but you can set these all the way up to 16 vCPU and 120GB of RAM if needed.
On my newly created AWS account I only had a quota of 6 vCPU for Fargate. So I could have theoretically run up to 40 concurrently but then i would have had to included better error handling to deal with some of the runs getting throttled. I have seen a quota value of 4000 vCPU in other AWS accounts so you can certainly scale this a lot higher if needed.
In my example case we are not really doing the expected long running business logic to save on costs and time but we will deserialize the array of transactions into a Rust vector and count the number of transactions and the total sales at the location for the day. This information will be sent back to the Step Function using the Task Token.
The flow in this example is that the Fargate task gets an S3 bucket name and object key which it downloads a file from and processes it.
Here is a snippet of the code:
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
// Need these key values to know what to process and how to send status
let task_token = env::var("TASK_TOKEN").expect("No task token was set");
let s3_bucket = env::var("S3_BUCKET").expect("No S3 bucket was set");
let s3_key = env::var("S3_KEY").expect("No S3 key was set");
// Want to keep track of processing time
let run_time = Instant::now();
let s3_client = S3_Client::new(&config);
// Get the file from S3 and save locally
let download_s3_result = download_object(&s3_client, &s3_bucket, &s3_key).await;
match download_s3_result {
Ok(filename) => {
println!("s3 download worked {}\n", filename);
input_file = filename.to_string();
}
Err(e) => println!("s3 download problem: {e:?}"),
}
// Get local file path of the S3 data
let json_file_path = Path::new("/tmp/").join(&input_file);
let file = File::open(json_file_path).expect("Error opening file we just saved to");
// Deserialize array of JSON Transactions into vector of objects
let transaction_vec: Vec<Transaction> =
serde_json::from_reader(file).expect("Error parsing json file");
let item_line_count = transaction_vec.len();
// Calculate total sales for the json data
let mut total_sales: f32 = 0_f32;
for next_transaction in transaction_vec {
total_sales = total_sales
+ (next_transaction
.Quantity
.parse::<f32>()
.expect("Error processing sales transaction quantity")
* next_transaction
.UnitPrice
.parse::<f32>()
.expect("Error processing sales transaction unit price"))
}
println!("Total sales is {}", total_sales);
println!("Before business logic processing");
// Sleep to simulate real business logic processing data
let num = rand::thread_rng().gen_range(4..20);
thread::sleep(Duration::from_secs(num));
println!("After business logic processing");
let sfn_client = sfn::Client::new(&config);
// Send back the task token to state machine to mark this processing run as successful
if task_token.len() > 0 {
let response = json!({
"status": "Success",
"store_number": input_file[6..input_file.len()-4],
"processing_time": format!("{} seconds", run_time.elapsed().as_secs()),
"item_transaction_count": item_line_count,
"total_sales": format!("${:.2}", total_sales)
});
let success_result = sfn_client
.send_task_success()
.task_token(task_token)
.output(response.to_string())
.send()
.await;
match success_result {
Ok(_) => {
println!("Sucessfully updated task status.")
}
Err(e) => println!("Error updating task status error: {e:?}"),
}
}
I have also enabled the AWS Distribution for Open Telemetry (https://aws.amazon.com/otel/) in the Fargate Tasks. This runs as a sidecar container and sends metrics to Cloudwatch. Here is an example of what metrics you can see from it. It has tons of options but this is just the basic stats.
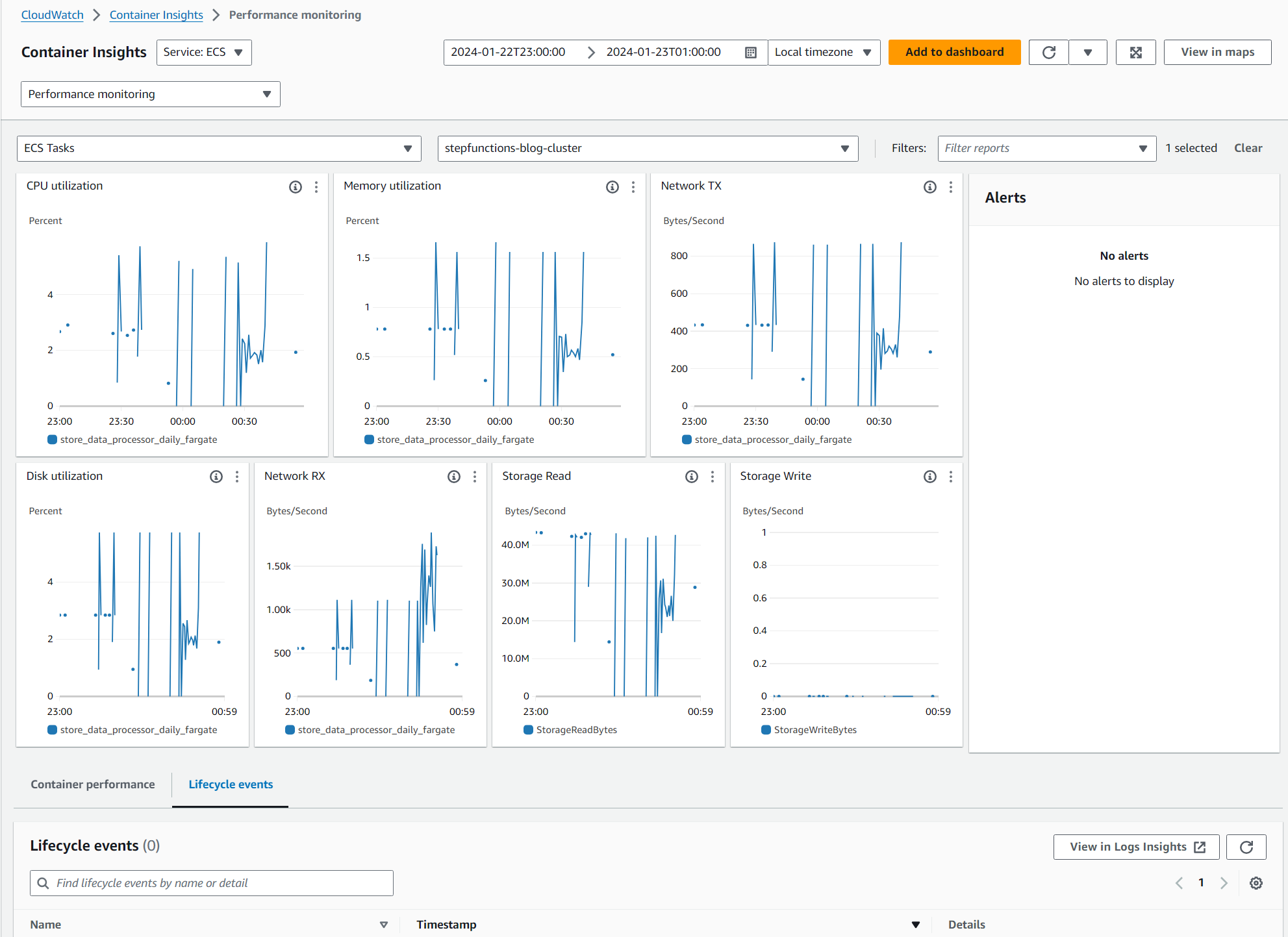
Here is a look at Fargate Task Definition each container has:
Putting it all together
Once all of the processing is done in Fargate the Step Function gets all the outputs and sends the results to the slack channel.
Here is a screenshot of the step function after it's all done.
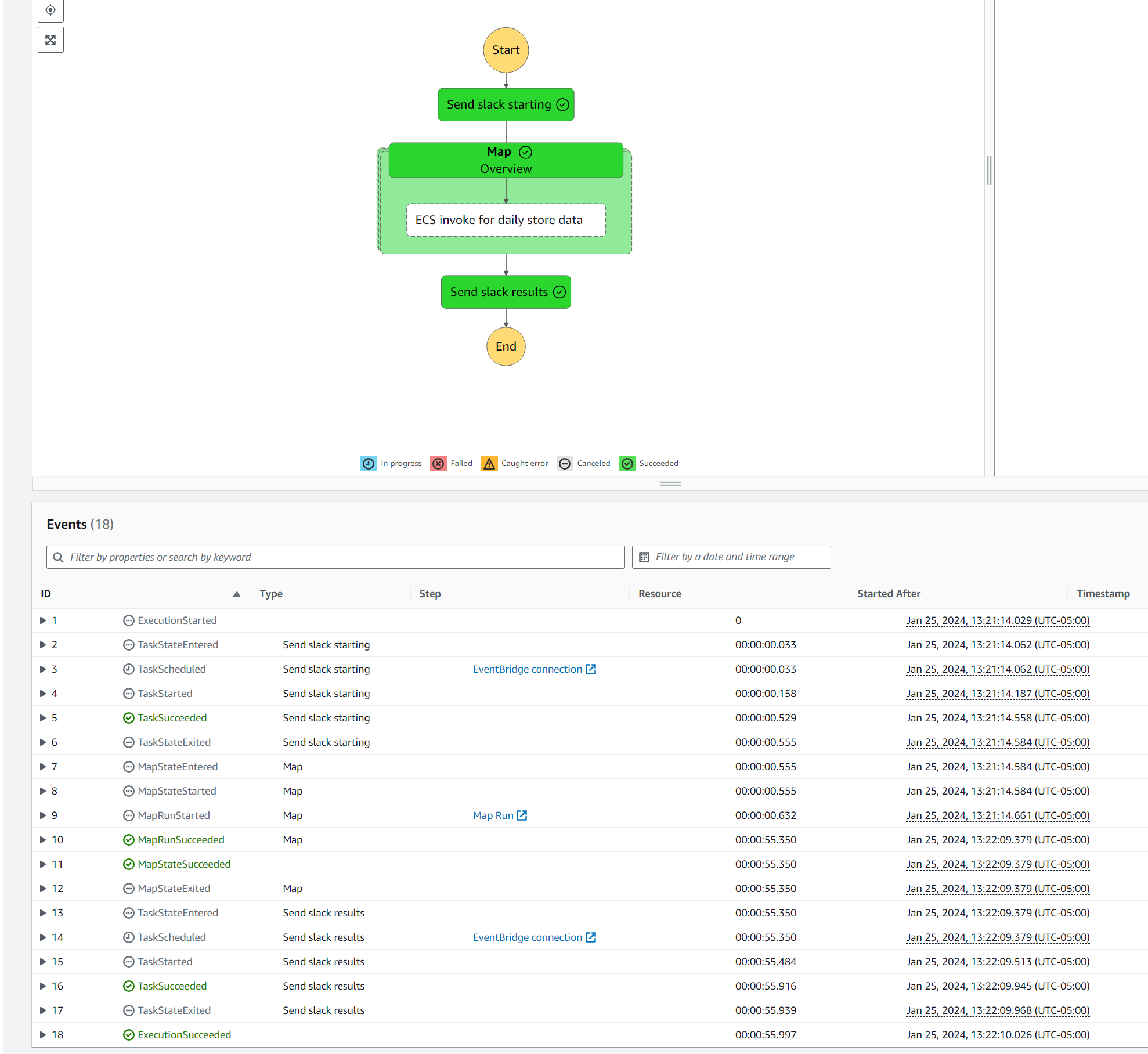
Here is an example of what gets pushed to Slack:
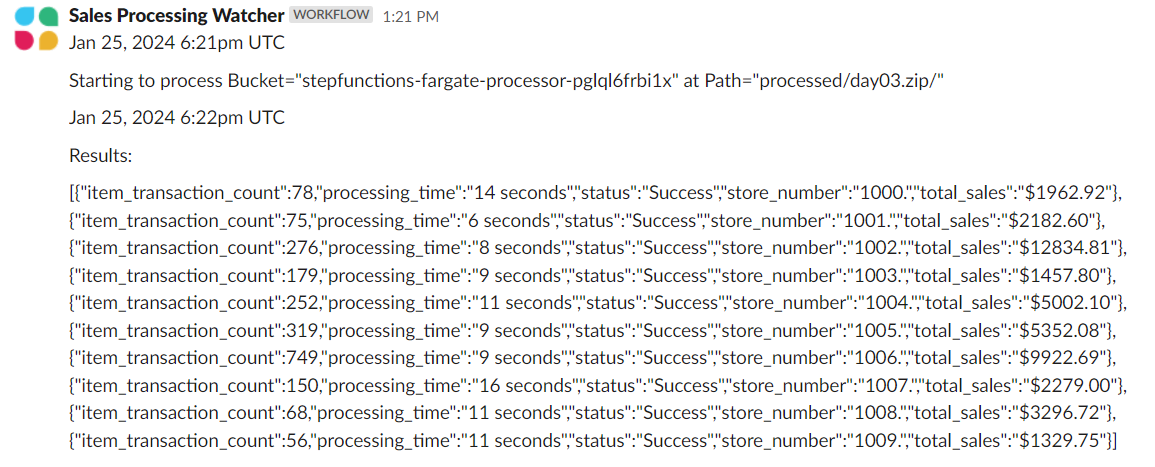
If you want to try this out for yourself I have included all the code in my github repo here https://github.com/RDarrylR/step-functions-fargate-processor. There are steps in the readme on how to install and test the solution out. It uses Terraform to setup most of the infrastructure along with cargo lambda (https://www.cargo-lambda.info/guide/getting-started.html) to package the Rust lambda function.
I have lots of plans to expand on this in the future and will post more as it's available.
For more articles from me please visit my blog at Darryl's World of Cloud or find me on X, LinkedIn, Medium, Dev.to, or the AWS Community.
For tons of great serverless content and discussions please join the Believe In Serverless community we have put together at this link: Believe In Serverless Community
Comments
Loading comments...